 ChatGPT和GPT-4等大型语言模型(LLM)近来备受瞩目,人们对其强大功能充满了无限遐想。然而,斯坦福大学的研究揭示了人们对大型语言模型(LLM)能力的误解,并呼吁消除这些误解。
ChatGPT和GPT-4等大型语言模型(LLM)近来备受瞩目,人们对其强大功能充满了无限遐想。然而,斯坦福大学的研究揭示了人们对大型语言模型(LLM)能力的误解,并呼吁消除这些误解。
研究表明,对于大型语言模型(LLM)的认知仅仅是冰山一角。涌现能力是大型语言模型(LLM)一度被认为具备的神秘特质,但斯坦福大学的研究人员通过选择适当的评估指标,证明了涌现能力实际上是一种幻象。
他们引入了阈值条件评估作为一种新的评估方法,用于确定大型语言模型(LLM)在任务上是否超过了某个阈值。研究结果表明,当使用正确的评估指标时,大型语言模型(LLM)的性能与小模型相差无几。因此,大型语言模型(LLM)的性能提升主要是由于规模的增加,而非真正的涌现能力。
这项研究对于消除人们对大型语言模型(LLM)能力的误解至关重要。它提醒我们不要过分夸大大型语言模型(LLM)的能力,并指出追求规模增加并非创造更好大型语言模型(LLM)的唯一途径。
尽管大型语言模型(LLM)在处理复杂语言任务方面存在一定局限性,但这项研究为未来的研究和发展提供了指导。正确选择评估指标的重要性不可忽视,同时也需要以更加准确客观的方式对待大型语言模型(LLM)。
大型语言模型(LLM)如GPT-4在应用中的涌现能力可能是一种幻象。了解这一点有助于消除人们对大型语言模型(LLM)的误解,并推动相关研究更加准确地发展。揭示大型语言模型(LLM)的真实能力将有助于我们充分利用其应用潜力,超越幻象。
为什么大型语言模型(LLM)的涌现能力会被炒作
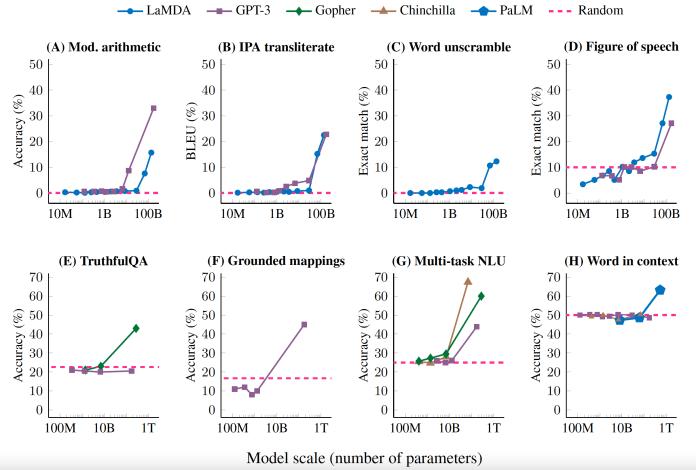
斯坦福大学的最新研究对大型语言模型(LLM)所谓的涌现能力提出了不同的观点。根据他们的研究,人们通常对大型语言模型(LLM)的涌现能力产生误解,这主要是因为在评估模型性能时选择了不同的指标,而非模型规模的影响。研究人员指出,“现有关于涌现能力的说法实际上是研究人员分析的结果,并不是模型在特定任务中随着规模增加而表现出的行为变化。”他们强调,涌现能力可能并非是扩展AI模型的固有特性。
具体而言,研究人员发现,涌现能力似乎只在非线性或不连续地缩放每个令牌错误率的指标下出现。这意味着在衡量任务性能时,某些指标可能显示出大规模的涌现能力,而另一些指标则显示出持续的改进。
举例来说,有些测试仅仅计算大型语言模型(LLM)输出的正确令牌数量。这种情况在涉及分类和数学相关任务时尤为常见,只有当所有生成的令牌都是正确的时,输出才被认为是正确的。
事实上,大型语言模型(LLM)输出的令牌逐渐接近正确的令牌。然而,由于最终答案与基本事实不符,这些输出被归类为不正确,直到达到所有令牌均为正确的阈值为止。
研究人员在他们的研究中发现,当使用不同的指标评估相同的输出时,涌现能力消失,而大型语言模型(LLM)的性能平衡提高。这些指标衡量的是到达正确答案所需的线性距离,而不仅仅是计算正确答案。
他们进一步尝试在其他类型的深度神经网络中重现涌现能力的情况,如视觉任务和卷积神经网络(CNN)。测试结果表明,如果使用非线性指标评估大型语言模型(LLM)的性能,将观察到类似的涌现能力现象。
这一研究的重要性在于提供了对大型语言模型(LLM)性能的关键视角。鉴于大型语言模型(LLM)的惊人能力和成就,人们倾向于将其拟人化或与其不具备的特性联系起来。
该研究的结论具有重要意义,因为它们将有助于更清晰地认识大型语言模型(LLM)领域,并更好地理解扩大模型规模的影响。正如Sam Bowman最近发表的一篇论文中所指出的:“当实验室投资于训练新的大型语言模型(LLM)并逐步扩大规模时,他们可能期望获得具有经济价值的各种新能力,但他们几乎无法对这些能力进行可靠预测,也不知道如何负责任地部署这些能力。”借助更好的技术手段来衡量和预测改进,研究人员将能够更好地评估扩大大型语言模型(LLM)规模的效益和风险。
这种方法还有助于鼓励研究人员探索创建更大型语言模型(LLM)的替代方案。虽然只有大型科技公司能够负担起训练和测试大型LLM的成本,但较小规模的公司也可以研究较小模型。有了这些指标,他们将能够更好地探索这些较小型语言模型的功能,并找到改进的新研究方向。